




本記事では、なぜ今「昔ながらの技術」が重要なのか、そして未経験からスペシャリストになるための最適な学習ロードマップを解説します。
「クラウドならOS知識は不要」という誤解
現代のクラウドインフラは、物理的なサーバー管理をAPIの裏側に隠蔽してくれました。KubernetesやAWS Lambdaの普及により、「OSさえ意識しなくていい」という風潮があります。しかし、これは大きな誤解です。
筆者自身、駆け出しの頃は「TerraformでEC2を立てれば終わり」と思っていました。ところが初めての本番障害で、コンテナが突然落ちる現象に遭遇。クラウドのステータスページを眺めながら途方に暮れた経験があります。その時に「Linuxカーネルを知らないと詰む」と痛感しました。
クラウドの管理画面(コントロールプレーン)は自動化されていますが、実際にプログラムを動かし、パケットを処理しているのは、依然としてLinuxカーネルであり、物理的なCPUやメモリです。
この構造を理解していないと、システムが正常なときは良くても、トラブルが起きた瞬間に「何が起きているか全くわからない(ブラックボックス)」状態に陥ります。クラウドエンジニアを目指す方が最初に学ぶべきスキルについては、クラウドエンジニア初心者が最初に学ぶべき5つのスキルも参考にしてください。
障害対応の「崖」:知識がないと詰む3つの事例
「クラウドが遅い」「コンテナが落ちる」といった現代的なトラブルの多くは、実はクラウドの不具合ではなく、「古典的」な物理現象やOSの挙動に起因します。
① メモリ不足(OOM Killer)とページキャッシュの罠
KubernetesでポッドがOOMKilled(メモリ不足で強制終了)になった際、知識のないエンジニアは単純に「メモリ割り当てを増やそう」と考え、コストを増大させます。
しかし、Linuxの知識があれば、以下の可能性を疑うことができます。
- OSがディスクI/O高速化のためにメモリを「ページキャッシュ」として使いすぎているのではないか?
- カーネルパラメータ(
vm.swappinessなど)の設定により、メモリ解放が間に合っていないのではないか?
② DNS障害と「Conntrack」の枯渇
「DNSの名前解決が時々失敗する」という現象に対し、クラウドの知識しかないと「AWSの障害かな?」とステータスページを眺めることしかできません。
しかし、オンプレミスの知識があれば、Linuxのファイアウォール機能における「Conntrack(接続追跡)テーブル」の溢れを疑うことができます。
③ ストレージ性能と「トークンバケット」
データベースが遅いのにCPU使用率が低い場合、知識があれば「CPUがディスクの書き込み完了を待っている(iowait)」状態であることを見抜けます。AWSのEBSはバーストクレジットが枯渇すると急激に遅くなります。
これらの障害は、Google検索だけでは解決できません。「なぜそうなるのか」という原理原則の理解があって初めて、適切な対処が可能になります。
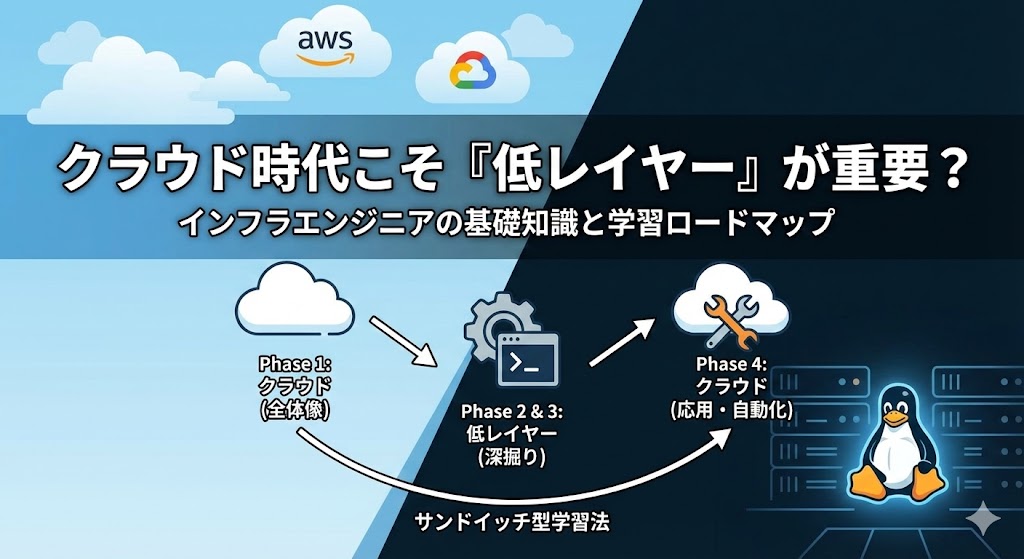
最短で成長する「サンドイッチ型」学習ロードマップ
まずはAWS/GCPのコンソールを触り、Webサーバーを立ててみる。EC2インスタンスの起動、NginxのインストールやセキュリティグループのABCを体験するのがゴールです。
⚡ Phase 1の実践環境を今すぐ作る — ConoHa VPS(時間課金・即時起動)
GUI禁止、CLI(黒い画面)のみで操作し、VPCウィザードを使わず手動でネットワークを設計します。「つながらない」経験を通じてTCP/IPを体感する。Linuxコマンドの基本はよく使う基本コマンド10選で固めておきましょう。
topコマンドやstraceを使って、プロセスやカーネルがどう動いているかを可視化する「デバッグ力」を養います。フロントエンドのパフォーマンスにも影響するキャッシュ戦略についてはSPAの帯域圧迫を解決する3つのキャッシュ戦略【インフラからReact Queryまで】も参考になります。
TerraformやAnsibleで自動化を行います。Phase 2・3の知識があるため、「なぜその設定が必要か」を理解した上でコードが書けるようになります。
実践環境を手に入れる:おすすめのVPS比較
学習には「壊してもいいサーバー」が必須です。AWS無料枠も良いですが、期限を気にせず使える国内VPSサービスなら、より気軽に実験できます。AWS無料枠の詳細はAWS無料枠まとめ:できること・注意点・安全な使い方もご確認ください。
| サービス | 最安プラン | 特徴 | おすすめ対象 |
|---|---|---|---|
| ConoHa VPS | 1時間1.3円〜 | 時間課金・即時起動・SSD全プラン | まず試してみたい初心者 |
| さくらのVPS | 月額698円〜 | 老舗の安定性・2週間無料試用 | 長期運用・コスパ重視 |
| XServer VPS | 月額830円〜 | 国内シェアNo.1エックスサーバー運営 | サポート重視・本格学習 |
⚡ ConoHa VPS で学習環境を今すぐ構築する(時間課金・即時起動)
よくある質問(FAQ)
低レイヤーの勉強はどのくらい時間がかかりますか?▼
クラウド資格を先に取るべきですか?▼
VPSとクラウド(AWS)はどう違いますか?▼
Linuxの知識がゼロでも始められますか?▼
結論:学習コストは「保険料」である
障害発生時、インターネット検索で解決策を探す「Google駆動型」の対応は、複雑な障害には通用しません。最悪の場合、誤ったコマンドでデータを破壊するリスクさえあります。
平時に基礎知識を学ぶコストは高いように感じるかもしれませんが、それは「システムダウンによるビジネス損失」を防ぐための保険料です。「クラウドしか知らない」エンジニアから一歩抜け出し、中身を理解した「T型人材」を目指していきましょう。








コメント